Programming Paradigm
 |
Programming Paradigm
- A programming paradigm is a fundamental style of computer programming.
- There are four main paradigms: imperative, declarative, functional (which is considered a subset of the declarative paradigm) and object-oriented.
Imperative paradigm
➯specify both what and How
- Procedural and object-oriented programming belong under imperative paradigm that you know from languages like C, C++, C#, PHP , Java and of course Assembly.
- Your code focuses on creating statements that change program states by creating algorithms that tell the computer how to do things. It closely relates to how hardware works. Typically your code will make use of conditional statements, loops and class inheritance.
Example of imperative code in JavaScript is:
class Number {
constructor (number = 0) {
this.number = number;
}
add (x) {
this.number = this.number + x;
}
}
const myNumber = new Number (5);
myNumber.add (3);
console.log (myNumber.number); // 8
Declarative paradigm
➱specify what to do, not how to do it
- Declarative programming is a programming paradigm in which the programmer defines what needs to be accomplished by the program without defining how it needs to be implemented.
- In other words, the approach focuses on what needs to be achieved instead of instructing how to achieve it.
- It is different from an imperative program which has the command set to resolve a certain set of problems by describing the steps required to find the solution.
- Declarative programming describes a particular class of problems with language implementation taking care of finding the solution.
- The declarative programming approach helps in simplifying the programming behind some parallel processing applications.
Example :
Real-World Example
- Librarian, please check me out a copy of Moby Dick. (Librarian, at their discretion chooses the best method for performing the request)
the declarative code in JavaScript:
const sum = a => b => a + b; console.log (sum (5) (3)); // 8
Different Between Imperative and Declarative

- Declarative programming refers to code that is concerned with higher levels of abstraction.
- Imperative programming refers to code that is concerned with lower levels of abstraction.
- Declarative programming tells the machine what you would like to happen (and the computer figures out how to do it)
- Imperative programming tells the machine how to do something (resulting in what you want to happen)
Functional Programming
➯Functional programming is used in languages like Lisp, Haskell, and Scala.
- The main difference between imperative and functional languages is that functions that are evaluated are the main way of gaining and transforming data, functional programming is stateless. Rather than assigning values which can then be mutated like what happens in imperative languages, the value returned by a function is only dependent on its input.
- The lack of state allows a functional language to be reasoned just by looking at a function’s input and output.

for and while loops, recursion is used instead. Most people are exposed to recursion in imperative languages,
but functional languages can have special support for recursion (such a tail call). Recursion is just the idea of one’s own definition to define itself.
➠It may seem counter-intuitive, but it actually is more prevalent than you might expect.
POSITIVE ABOUT FUNCTIONAL PROGRAMMING
- The great benefit to functional programming is that if you’re disciplined about state you’ll have a much better time.
- Because changes with the outside world are pushed farther and farther apart, you can, when using the paradigm, spend very little time with a head-scratchier (so common in WordPress) of “how did that possibly get to that state?” Pure, mathematical functions are easier to comprehend than ones that do magic.
- That’s the big advantage–being disciplined about state makes state much easier to think about and understand.
- It has another advantage too: massive parallelization is possible.
- What that means is that as computers are increasingly getting more cores rather than faster processors, your program can better take advantage of them.
- Few programs today take advantage of this trait, but it’s a big benefit to the paradigm.
BAD ABOUT FUNCTIONAL PROGRAMMING
- The big thing that I think makes functional programming bad is that you’re going to quickly come up against your not having a PhD in mathematics or computer science or some logic-heavy discipline.
- I have a pretty good understanding of functional programming (FP) for a non-functional-programmer. But there are kind-of-important buzzwords I couldn’t begin to understand which people talk about a lot when they talk about functional programming.
- “Functor”, “monoid”, etc are much harder to wrap your head around than objects.
- The other related disadvantage, is that you’re doing a lot of putting functions into functions into functions.
- And just as I’m not a computer, I’m also no math wiz. So all the complex operations that functional programmers do a lot are pretty abstract to me and I can feel overwhelmed.
I know this was true of other paradigms for me, and it’s just a bigger learning curve, but it’s certainly nothing to shrug off quickly.
Procedural Programming
➯Procedural programming is a programming paradigm that uses a linear or top-down approach.
➤It relies on procedures or subroutines to perform computations.
➤Procedural programming is also known as imperative programming.
A procedural language, as the name implies, relies on predefined and well-organized procedures, functions or subroutines in a program’s architecture by specifying all the steps that the computer must take to reach a desired state or output.
➤The procedural language segregates a program within variables, functions, statements and conditional operators. Procedures or functions are implemented on the data and variables to perform a task. These procedures can be called/invoked anywhere between the program hierarchy, and by other procedures as well. A program written in procedural language contains one or more procedures.
➤Procedural language is one of the most common types of programming languages in use, with notable languages such as C/C++, Java, ColdFusion and PASCAL.
GOOD THINGS ABOUT PROCEDURAL PROGRAMMING
- That said, some really good things come out of procedural programming too. The first and most important is that it’s not over-abstracted, which can be a real help for newcomers.
- Understanding objects generally seems to feel more complicated to newcomers than a few function calls.
- Procedural programs can also be faster than most alternatives.
- This is especially true historically.
- You easily get the maximum performance out of procedures because you’re “empathetic” to what the machine’s most efficient way to perform a task is. If you can do it in one call rather than 500, when you write procedural code you generally realize and do this.
NEGATIVE THINGS ABOUT PROCEDURAL PROGRAMMING
- The biggest knock against procedural programming is really that it’s among the oldest ways of programming. As a result of this, it’s derided as outmoded and generally not very cool. But those are pretty soft complaints. More concrete complaints that I think are good:
- It is often hard to think clearly about the overriding program. Naming procedures with functions can help to simplify the machine-like nature of the procedural code, but fundamentally the way humans and computers think aren’t that similar, so code that hews too close to what machines like confuses humans often.
- There are no abstractions. Good programs abstract simple things from more complex underlying realities. They favor human comprehension over machine efficiency. There are times when you can’t have this for performance reasons, and in those cases, a procedural code can be faster and thus better.
Lambda Calculus
Lambda calculus is a framework developed by Alonzo Church in the 1930s to study computations with functions.
- Function creation − Church introduced the notation λx.E to denote a function in which ‘x’ is a formal argument and ‘E’ is the functional body. These functions can be of without names and single arguments.
- Function application − Church used the notation E1.E2 to denote the application of function E1 to actual argument E2 . And all the functions are on a single argument.


The Syntax of Lambda Calculus
Lambda calculus includes three different types of expressions, i.e.,
E :: = x (variables)
| E1 E2 (function application)
| λx.E (function creation)
Where λx.E is called Lambda abstraction and E is known as λ-expressions.
Evaluating Lambda Calculus
- Pure lambda calculus has no built-in functions. Let us evaluate the following expression −
(+ ( * 5 6) (*8 3))
- Here, we can’t start with '+' because it only operates on numbers. There are two reducible expressions:
(* 5 6) and (* 8 3).
- We can reduce either one first. For example −
(+(* 5 6) (* 8 3))
(+ 30(* 8 3))
(+ 30 24)
=(54)
β-reduction Rule
- We need a reduction rule to handle λs
(λx . * 2 x) 4
(* 2 4)
=(8)
- This is called β-reduction.
- The formal parameter may be used several times −
( λx . x x ) 4
( + 4 4 )
= (8)
- When there are multiple terms, we can handle them as follows −
(λx .( λx . + (- x 1 ))x 3) 9
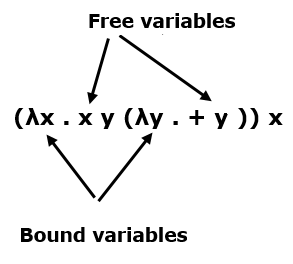
Free and Bound Variables
In an expression, each appearance of a variable is either "free" (to λ) or "bound" (to a λ).
β-reduction of (λx . E) y replaces every x that occurs free in E with y. For Example −
Alpha Reduction
Alpha reduction is very simple and it can be done without changing the meaning of a lambda expression.
λx.(λx . x) (+ 1 x) ↔ a λx . (λy . y ) ( +1 x )
For example −
( λx . ( λx . + ( - x 1) ) x 3 ) 9
( λx . (λy . + ( - y 1 ) ) x 3 ) 9
( λy . + ( - y 1 )) 9 3
+( - 9 1 ) 3
+ 8 3
11
Church-Ross er Theorem
The Church-Rosser Theorem states the following −
- 🔼If E1 ↔ E2, then there exists an E such that E1 → E and E2 → E.
- “Reduction in any way can eventually produce the same result.”
- 🔼If E1 → E2, and E2 is normal form, then there is a normal-order reduction of E1 to E2.
- “Normal-order reduction will always produce a normal form, if one exists.”
Referential Transparency
➯A function that returns always the same result for the same input is called a pure function.
➯ A pure function therefore is a function with no observable side effects, if there are any side effects on a function the evaluation could return different results even if we invoke it with the same arguments.
➯ A pure function therefore is a function with no observable side effects, if there are any side effects on a function the evaluation could return different results even if we invoke it with the same arguments.
➯We can substitute a pure function with its calculated value, for example:
def f(x: Int, y: Int) = x + y
➯for the input
f(2, 2) can be replaced by,4 it is like a big lookup table.
➯We can do so because it does not have any side effects.
➯The ability to replace an expression with its calculated value is called referential transparency.
➯Referential transparency is important because it allows us to substitute expressions with values.
➯This property enables us to think and reason about the program evaluation using the substitution model.
➯ Hence, we can say that expressions that can be replaced by values are deterministic, as they always return the same value for a given input.
➣This means that a function should not have any side effects.
➢ It should take input variables, not modify those variables, then calculate and return something new.
➢Unlike object-oriented programming, you should not change (mutate) the state of other variables, even if those variables are (a) variables of your class or (b) variables that were passed into your function/method.
Benefits of functions not having side effects
 3. Inheritance
3. Inheritance






✦The JavaScript language is very flexible and quite tolerant of obtuse programmatic constructs. So how do you write a compiler for a late-binding, loosely-typed, dynamic language? Before you make it fast you must first make it accurate, or as Brendan Eich puts it,
🌟The principal problem with the classic architecture is that runtime bytecode interpretation is slow. The performance can be improved with the addition of a compilation step to convert the bytecode into machine code. Unfortunately waiting several minutes for a web page to fully compile isn’t going to make your browser very popular.
🌠The first JavaScript JIT compiler was Mozilla’s TraceMonkey. This was a “tracing JIT” so-called because it traces a path through your code looking for commonly executed code loops. These “hot loops” are then compiled into machine code. With this optimization alone Mozilla was able to achieve performance gains of 20% to 40% over their previous engine.







Referential Transparency in Programming
In programming,
referential transparency applies to programs. As programs are composed of subprograms, which are programs themselves, it applies to those subprograms, too.
referential transparency applies to programs. As programs are composed of subprograms, which are programs themselves, it applies to those subprograms, too.
Subprograms may be represented, among other things, by methods.
That means the method can be referentially transparent, which is the case if a call to this method may be replaced by its return value:
int add(int a, int b)
{
return a+ b;
}
int mult (int a, int b)
{
return a* b;
}
int x = add(2 , mult (3 , 4) );
"No Side-Effects " in Functional Programming
➢ It should take input variables, not modify those variables, then calculate and return something new.
➢Unlike object-oriented programming, you should not change (mutate) the state of other variables, even if those variables are (a) variables of your class or (b) variables that were passed into your function/method.
Benefits of functions not having side effects
If you're new to functional programming this may sound pretty hardcore, but as someone who has been working with Scala and functional programming for a few months now, I do find it a good practice to try to follow. Here's a short list of benefits from this Scala programming idiom:
- Methods are less entangled.
- They are therefore more reliable and reusable.
- You won't change someone's variable accidentally, and they won't change yours.
- Make your programs easier to test.
I started to write why each of these statements is true, but they all come down to the same things:
- Because you aren't mutating the variables passed to you, you can't corrupt their values.
- Because your function has no other side effects other than calculating a value based on its inputs, there are no side effects you need to test.
Object Oriented Programming
➤Object oriented programming is one of the newest and most powerful paradigms.
The Object-Oriented Programming mentions to the programming methodology based on the objects, in its place of just procedures and functions.
These objects are planned into classes, which are allowing the individual objects to be group together.
➤Modern programming languages containing java, PHP and C or C++ are object-oriented languages
➤The "object" in an Object Oriented Programing language discusses an instance or specific type, of the class.
➤Each and every object has a structure related to other objects in the class, but it can be allocated individual features.
➤An object can also call a method or functions, particular to that object.
➤The Individual characters are may be defined as objects, according to the object which allows them to have different skill, appearances, and abilities. Object-oriented programming makes it easier for programmers to design and organize software programs.
➤The important features which are helping to design the object-oriented programming and design are given below:
➯' Development over the designed programming paradigm.
➯' Importance on data rather than algorithms.
➯' Procedural abstraction is perfected by data abstraction.
➯' Data and associated processes are unified, grouping objects with common attributes, operations, and semantics
The Principles of OOP
According to the principals there twelve fundamental features there are given below.
1. Encapsulation
2. Data Abstraction
 3. Inheritance
3. Inheritance
4. Polymorphism
5. Extensibility
6. Persistence
7. Delegation
8. Generality
9. Object Concurrency
10. Event Handling
11. Multiple Inheritance
12. Message Passing
According to the Object Oriented programming language, it has to allow working with classes and objects as well as the implementation and use of the main four fundamental object-oriented principles and concepts.
- Encapsulation
- Inheritance
- Polymorphism➠Polymorphic which means 'many forms' has Greek roots. Poly ' Many, Morphos ' forms in object-oriented programming Polymorphism means that it has many forms.➠Polymorphism allows an object to be processed differently by data types and/or data classes. More precisely, it is the ability for different objects to respond to the same message in different ways.➠In the above figure 4, it is shown that a simple thread could be transformed into different shapes the same way polymorphism means that it could change to many different types. ➠ It allows a single name or operator to be associated with different operations, depending on the type of data it has passed and gives the ability to redefine a method within a derived class.
- Data abstraction➠Abstraction is a concept which facilitates to extract out the essential information of an object.➠Abstraction facilitates the easy conceptualization of real-world objects, by eliminating the unnecessary details of the object. ➠ Unnecessary details? Yes, all the similar objects when you generalize, you will drop the uncommon details about the objects. In OOP (Object orients programming), Abstraction Facilitates the easy conceptualization of real-world objects into the software program.
➠The process, or mechanism, by which you combine code and the data it manipulates into a single unit, is commonly referred to as encapsulation.
➠Encapsulation provides a layer of security around manipulated data, protecting it from external interference and misuse. In Java, this is supported by classes and objects.
➠New data types (classes) can be defined as extensions to previously defined types.
➠Parent Class (Super Class) Child Class (Sub Class) Subclass inherits properties from the parent class. Parent-Child
Event-Driven Program
🌞An event-driven program is one that largely responds to user events or other similar input.
⇒The concept of event-driven programming is an important one in application development and other kinds of programming and has spawned the emergence of event handlers and other resources.
⇒An event-driven program is also known as an event-driven application.
The idea in event-driven programming is that the program is designed to react.
⇒It reacts to specific kinds of input from users, whether it's a click on a command button, a choice from a drop-down list, an entry into a text box, or other kinds of user events.
⇒Other programming languages may feature user events that are largely delivered through a command-line interface or some other type of user interface.
⇒The opposite of event-driven programming would be programming that is written to act regardless of user input.
⇒For example,
➮ Display apps such as those for weather updates or sports scores may feature less of the event-driven programming that is inherent in other kinds of programs.

⇒ However, nearly all software relies on user events for functionality, and it would be easy to argue that event-driven programming is the default for nearly all kinds of projects.
⇒That's because, in general, applications and code modules are written to respond to human actions, which is part of the core concept of how humans work with machines. However, identifying event-driven aspects of programs can be helpful in design analysis.
Difference between various paradigms
The Primary differences between each type of programming paradigms are described below.

Markup Language
➤A markup language is a computer language that uses tags to define elements within a document. They are easier to read.
➤ These languages are designed to create a structure, identify data or to present data rather than to execute an action or to perform an action.
➤ The text present in the tags is structured by the web browser accordingly.
➤HTML, XML, and XHTML are some common markup languages. HTML stands for HyperText Markup Language.
➤It is used to create the structure of a web page. The file is divided into two sections called the head and the body.
➤The head section contains the metadata, title etc. The body contains the visible elements of the page. There are tags for tables, forms, paragraphs, headings and many more.

➤XML stands for Extensible Markup Language. XML tags are used to store and organize data.
➤It is platform and language independent. XML helps to share data between completely different platforms.
➤ It is used with databases, programming languages, and mobile applications.
➤ Moreover, XHTML stands for Extensible HyperText Markup Language.
➤ It is a combination of both HTML and XML. XML parser are used to parse these XHTML documents.
⭐A markup language is used to control the presentation of data, like "represent these usernames as a bullet list or as a table".
Scripting Languages
★A scripting language is a type of language that is designed to integrate and communicate with other programming languages.
★ Examples of commonly used scripting languages include JavaScript, VBScript, PHP among others. There are mostly used in conjunction with other languages, either programming or markup languages.
★For example, PHP which is a scripting language is mostly used in conjunction with HTML.
☆It is safe to say that all scripting languages are programming languages, but not all programming languages are scripting languages.
★One of the differences between scripting languages and programming languages is in terms of compilation.
★While it is a must for programming to be compiled, scripting languages are interpreted without being compiled. It is important to note that scripting languages are interpreted directly from the source code.
★Due to the absence of the compilation process, scripting languages are a bit faster than the programming languages.
★In recent years, we have seen widespread use of scripting languages in developing the client side of web applications.
⭐A scripting language is used to mediate between programs in order to generate data. This is especially true of shell scripting languages like bash, but if you reflect about it, also Python or Perl came from the need to accomplish tasks in UNIX without writing a program in C. The program that you control most of the time in those languages is the interpreter of the language itself, which accomplishes general tasks for you. Other typical programs you interact with are database servers or web servers.
Going back to the user list metaphor, in a scripting language you ask the database "give me all user names", then ask the web server "send this user list to this requester".
Programming Languages
❂A programming language is simply a set of rules that tells a computer system what to do and how to do it. It gives the computer instructions for performing a particular task.
❂A programming language consists of a series of well-defined steps which the computer must strictly follow in order to produce the desired output.
❂Failure to follow the steps as it has been defined will result in an error and sometimes the computer system won’t perform as intended.

❂These instructions are usually written by programmers who have in-depth knowledge about a particular programming language.
❂They are not only knowledgeable about the syntax of that language but also they have mastered the data structures and algorithms used for that language.
❂ This is because the basic function of a programming language is to translate the input data into meaningful output.
✦Examples of programming languages include C, C++, Java, and Python.
🌻Most executables would like to do some useful task, like writing to the console. There is a set of machine instructions that will do this! I suppose that Real Men would have nonportable inline assembly blocks to express these instructions. But it is more productive to write them once for each system, and make them available in libraries. These collections form the runtime libraries for the system. Libraries can be .lib files ("static-libs" in Windows lingo), which are essentially repositories of object code which can be linked into your executables, or .so files (.dll on Windows) which are "dynamically linked" at runtime. Dynamic linking produces executables which are smaller but depend on the runtime availability of the library.
🌻A program does not absolutely need to execute directly on the machine running it. It could instead issue instructions to a standardized virtual machine, which would translate them to machine instructions. The virtual machine has the property that it looks the same to the program, regardless of what system it is running on. Java is the main exemplar of this practice. Java programs are compiled, not to native assembler, but to virtual machine instructions (colloquially known as "bytecode"). See also The LLVM Compiler Infrastructure Project
Program The Role Of the Virtual Runtime Machines
🌻Most executables would like to do some useful task, like writing to the console. There is a set of machine instructions that will do this! I suppose that Real Men would have nonportable inline assembly blocks to express these instructions. But it is more productive to write them once for each system, and make them available in libraries. These collections form the runtime libraries for the system. Libraries can be .lib files ("static-libs" in Windows lingo), which are essentially repositories of object code which can be linked into your executables, or .so files (.dll on Windows) which are "dynamically linked" at runtime. Dynamic linking produces executables which are smaller but depend on the runtime availability of the library.
🌻A program does not absolutely need to execute directly on the machine running it. It could instead issue instructions to a standardized virtual machine, which would translate them to machine instructions. The virtual machine has the property that it looks the same to the program, regardless of what system it is running on. Java is the main exemplar of this practice. Java programs are compiled, not to native assembler, but to virtual machine instructions (colloquially known as "bytecode"). See also The LLVM Compiler Infrastructure Project
🌻A virtual machine is a particular kind of interpreter -- it reads instructions in its own input format, not in assembler or machine code, then executes them somehow. An
evalblock in Python (or calling Python code embedded in C) evokes the Python interpreter.
🌻"Runtime system" is too vague for me to know what it means.
Find How the JS code is executed
When we talk about a JavaScript engine what we’re usually referring to is the compiler; a program that takes human-readable source code (in our case JavaScript) and from it generates machine-readable instructions for your computer. If you haven’t considered what happens to your code when it runs this can all sound rather magical and clever but it’s essentially a translation exercise. Making that code run fast is what’s clever.
How a simple compiler works
JavaScript is considered a high-level language, meaning it is human readable and has a high degree of flexibility. The job of the compiler is to turn that high-level code into native computer instructions.
JavaScript is considered a high-level language, meaning it is human readable and has a high degree of flexibility. The job of the compiler is to turn that high-level code into native computer instructions.

A simple compiler might have a four-step process: a lexer, a parser, a translator and an interpreter.
- The lexer or lexical analyzer (or scanner, or tokenizer) scans your source code and turns it into atomic units called tokens. This is most commonly achieved by pattern matching using regular expressions.
- The tokenized code is then passed through a parser to identify and encode its structure and scope into what’s called a syntax tree.
- This graph-like structure is then passed through a translator to be turned into bytecode. The simplest implementation of which would be a huge switch statement mapping tokens to their bytecode equivalent.
- The bytecode is then passed to a bytecode interpreter to be turned into native code and rendered.
☀ This is a classic compiler design and it’s been around for many years. The requirements of the desktop are very different however from those of the browser. This classic architecture is deficient in a number of ways. The innovative way in which these issues were resolved is the story of the race for speed in the browser.
Fast, Slim, Correct
✦The JavaScript language is very flexible and quite tolerant of obtuse programmatic constructs. So how do you write a compiler for a late-binding, loosely-typed, dynamic language? Before you make it fast you must first make it accurate, or as Brendan Eich puts it,
✦✦“Fast, Slim, Correct. Pick any two, so long as one is ‘Correct’”
✦An innovative way to test the correctness of a compiler is to “fuzz” it. Mozilla’s Jesse Ruderman created jsfunfuzz for exactly this purpose. Brendan calls it a “JavaScript travesty generator” because it’s purpose is to create weird but valid syntactic JavaScript constructs that can then be fed to a compiler to see if it copes. This kind of tool has been incredibly helpful in identifying compiler bugs and edge cases.
JIT compilers
🌟The principal problem with the classic architecture is that runtime bytecode interpretation is slow. The performance can be improved with the addition of a compilation step to convert the bytecode into machine code. Unfortunately waiting several minutes for a web page to fully compile isn’t going to make your browser very popular.
🌟The solution to this is “lazy compilation” by a JIT, or Just In Time compiler. As the name would suggest, it compiles parts of your code into machine code, just in time for you to need it. JIT compilers come in a variety of categories, each with their own strategies for optimization. Some like say a Regular Expression compiler is dedicated to optimizing a single task; whereas others may optimize common operations such as loops or functions. A modern JavaScript engine will employ several of these compilers, all working together to improve the performance of your code.
JavaScript JIT compilers
🌠The first JavaScript JIT compiler was Mozilla’s TraceMonkey. This was a “tracing JIT” so-called because it traces a path through your code looking for commonly executed code loops. These “hot loops” are then compiled into machine code. With this optimization alone Mozilla was able to achieve performance gains of 20% to 40% over their previous engine.
🌠Shortly after TraceMonkey launched Google debuted its Chrome browser along with its new V8 JavaScript engine. V8 had been designed specifically to execute at speed. A key design decision was to skip bytecode generation entirely and instead have the translator emit native code. Within a year of launch, the V8 team had implemented register allocation, improved inline caching and rewritten their regex engine to be ten times faster. This increased the overall speed of their JavaScript execution by 150%. The race for speed was on!
🌠More recently browser vendors have introduced optimizing compilers with an additional step. After the Directed Flow Graph (DFG) or syntax tree has been generated the compiler can use this knowledge to perform further optimizations prior to the generation of machine code. Mozilla’s IonMonkey and Google’s Crankshaft are examples of these DFG compilers.
🌠The ambitious objective of all this ingenuity is to run JavaScript code as fast as native C code. A goal that even a few years ago seemed laughable but has been edging closer and closer every since. In part 3 we’ll look at some of the strategies compiler designers are using to produce even faster JavaScript
The output of an HTML Document
🎄HTML is simply plain text with a bunch of tags, as others have answered. My suggestion, if you are doing something that is more complex than just outputting a basic HTML snippet, is to use a template engine such as StringTemplate.
🎋StringTemplate lets you create a text file (actually, an HTML file) that looks like this:
<html>
<head>
<title>Example</title>
</head>
<body>
<p>Hello $name$</p>
</body>
</html>
🌳That is your template. Then in your Java code, you would fill in the
$name$ placeholder like this and then output the resulting HTML page:StringTemplate page = group.getInstanceOf("page");
page.setAttribute("name", "World");
System.out.println(page.toString());
🌲This will print out the following result on your screen:
<html>
<head>
<title>Example</title>
</head>
<body>
<p>Hello World</p>
</body>
</html>
Of course, the above example Java code isn't the complete code, but it illustrates how to use a template that's still valid HTML (makes it easier to edit in an HTML editor) while keeping your Java code simple (by avoiding having a bunch of HTML tags in your
System.out.printlnstatements).
🌴As for MS Office .doc format, that is more complex and you can look into Apache POI for that.
CASE Tools
✅CASE tools are a set of software application programs, which are used to automate SDLC activities. CASE tools are used by software project managers, analysts and engineers to develop a software system.
There is a number of CASE tools available to simplify various stages of Software Development Life Cycle such as Analysis tools, Design tools, Project management tools, Database Management tools, Documentation tools are to name a few.
✅Use of CASE tools accelerates the development of a project to produce the desired result and helps to uncover flaws before moving ahead with the next stage in software development.
Components of CASE Tools
CASE tools can be broadly divided into the following parts based on their use at a particular SDLC stage:
- Central Repository - CASE tools require a central repository, which can serve as a source of common, integrated and consistent information. Central repository is a central place of storage where product specifications, requirement documents, related reports and diagrams, other useful information regarding management is stored. Central repository also serves as a data dictionary.

- Upper Case Tools - Upper CASE tools are used in planning, analysis and design stages of SDLC.
- Lower Case Tools - Lower CASE tools are used in the implementation, testing and maintenance.
- Integrated Case Tools - Integrated CASE tools are helpful in all the stages of SDLC, from Requirement gathering to Testing and documentation.
CASE tools can be grouped together if they have similar functionality, process activities and capability of getting integrated with other tools.The scope of Case Tools
- The scope of CASE tools goes throughout the SDLC.
Case Tools Types
Now we briefly go through various CASE toolsDiagram tools
These tools are used to represent system components, data and control flow among various software components and system structure in a graphical form. For example, Flow Chart Maker tool for creating state-of-the-art flowcharts.Process Modeling Tools
Process modelling is a method to create a software process model, which is used to develop the software. Process modelling tools help the managers to choose a process model or modify it as per the requirement of the software product. For example, EPF ComposerProject Management Tools
- hese tools are used for project planning, cost and effort estimation, project scheduling and resource planning. Managers have to strictly comply project execution with every mentioned step in software project management. Project management tools help in storing and sharing project information in real-time throughout the organization. For example, Creative Pro Office, Trac Project, Basecamp.
Documentation Tools
Documentation in a software project starts prior to the software process, goes throughout all phases of SDLC and after the completion of the project.Documentation tools generate documents for technical users and end users. Technical users are mostly in-house professionals of the development team who refer to system manual, reference manual, training manual, installation manuals etc. The end user documents describe the functioning and how-to of the system such as user manual. For example, Doxygen, DrExplain, Adobe RoboHelp for documentation, Analysis Tools
These tools help to gather requirements, automatically check for any inconsistency, inaccuracy in the diagrams, data redundancies or erroneous omissions. For example, Accept 360, Accompa, CaseComplete for requirement analysis, Visible Analyst for total analysis.Design Tools
These tools help software designers to design the block structure of the software, which may further be broken down in smaller modules using refinement techniques. These tools provide detailing of each module and interconnections among modules. For example, Animated Software DesignConfiguration Management Tools
An instance of software is released under one version. Configuration Management tools deal with –- Version and revision management
- Baseline configuration management
- Change control management
CASE tools help in this by automatic tracking, version management and release management. For example, Fossil, Git, Accu REV.Change Control Tools
These tools are considered as a part of configuration management tools. They deal with changes made to the software after its baseline is fixed or when the software is first released. CASE tools automate change tracking, file management, code management and more. It also helps in enforcing change policy of the organization.Programming Tools
- These tools consist of programming environments like IDE (Integrated Development Environment), in-built modules library and simulation tools. These tools provide comprehensive aid in building software product and include features for simulation and testing. For example, Cscope to search code in C, Eclipse.
Prototyping Tools
Software prototype is a simulated version of the intended software product. Prototype provides initial look and feel of the product and simulates few aspects of the actual product.Prototyping CASE tools essentially come with graphical libraries. They can create hardware independent user interfaces and design. These tools help us to build rapid prototypes based on existing information. In addition, they provide a simulation of a software prototype. For example, Serena prototype composer, Mockup Builder.Web Development Tools
These tools assist in designing web pages with all allied elements like forms, text, script, graphic and so on. Web tools also provide live preview of what is being developed and how will it look after completion. For example, Fontello, Adobe Edge Inspect, Foundation 3, Brackets.Quality Assurance Tools
Quality assurance in a software organization is monitoring the engineering process and methods adopted to develop the software product in order to ensure conformance of quality as per organization standards. QA tools consist of configuration and change control tools and software testing tools. For example, SoapTest, AppsWatch, JMeter.Maintenance Tools
Software maintenance includes modifications in the software product after it is delivered. Automatic logging and error reporting techniques, automatic error ticket generation and root cause Analysis are few CASE tools, which help software organization in the maintenance phase of SDLC. For example, Bugzilla for defect tracking, HP Quality Center.
CASE workbenches
⊗ A set of tools which supports a particular phase in the software process
⊗ Tools work together to provide comprehensive support
⊗ Common services are provided which are used by all tools and some data integration is supported
Types of workbench
Open workbenches
⊗ Control integration mechanisms are provided and the data integration protocols are public. New tools can, therefore, be added by users
Closed workbenches
⊗ Many commercial workbenches are closed systems. The control and data integration protocols are proprietary. These are more common than open workbenches ⊗ Allows for tighter tool integration including presentation integration
⊗ However, it is impossible to integrate third-party tools and the user is tied to a single supplier
Programming workbenches
⊗ A set of tools to support program development
⊗ First CASE workbenches. Include compilers, linkers, loaders, etc.
⊗ Programming workbenches are often integrated around an abstract program representation (the abstract syntax tree) which allows for tight integration of tools
⊗ Integration around shared source-code files is also possible
Language-directed workbenches
⊗ Integrated around an abstract program representation
⊗ The system editor has language knowledge and can edit the abstract representation rather than the source code text
⊗ A range of program analysis tools may be supported ⊗ Allow multiple views of the program to be generated

4GL workbenches
⊗ Provide facilities for developing 4GL programs
⊗ Integrated around a database management system
⊗ Components usually include
• Database query language
• Form design system
• Spreadsheet
• Report generator
⊗ Very effective in developing business systems

Design and analysis workbenches
⊗ Support the generation of system models during design and analysis activities
⊗ Usually intended to support a specific structured method
⊗ Provide graphical editors plus a shared repository
⊗ May include code generators to create source code from design information

Workbench advantages
⊗ Generally available on relatively cheap personal computers
⊗ Results in standardized documentation for software systems
⊗ Estimated that productivity improvements of 40% are possible with fewer defects in the completed systems
Testing workbenches
⊗ Testing is an expensive process phase. Testing workbenches provide a range of tools to reduce the time required and total testing costs
⊗ Most testing workbenches are open systems because testing needs are organization-specific
⊗ Difficult to integrate with closed design and analysis workbenches

Testing workbench adaptations
⊗ Scripts may be developed for user interface simulators and patterns for test data generators
⊗ Test outputs may have to be prepared manually for comparison
⊗ Special-purpose file comparators may be developed
Environment generation

Design workbench generation
⊗ Design and analysis workbenches can be created by using a method-definition language to define the method rules and guidelines
⊗ Components of a meta-CASE workbench include • General-purpose repository • Tools to create structure editors or textual notations and programming languages • A generic diagram editing system • Code generators for various languages • Forms and report generators

Difference between Framework, Library, and Plugin
⛄Actually, these terms can mean a lot of different things depending on the context they are used.
❆For example, on Mac OS X frameworks are just libraries, packed into a bundle. Within the bundle, you will find an actual dynamic library (libWhatever.dylib). The difference between a bare library and the framework on Mac is that a framework can contain multiple different versions of the library. It can contain extra resources (images, localized strings, XML data files, UI objects, etc.) and unless the framework is released to the public, it usually contains the necessary .h files you need to use the library.
🌨Thus you have everything within a single package you need to use the library in your application (a C/C++/Objective-C library without .h files is pretty useless, unless you write them yourself according to some library documentation), instead of a bunch of files to move around (a Mac bundle is just a directory on the Unix level, but the UI treats it like a single file, pretty much like you have JAR files in Java and when you click it, you usually don't see what's inside, unless you explicitly select to show the content).
Wikipedia calls the framework a "buzzword". It defines a software framework as
⛄A software framework is a re-usable design for a software system (or subsystem). A software framework may include support programs, code libraries, a scripting language, or other software to help develop and glue together the different components of a software project. Various parts of the framework may be exposed through an API..
❅So I'd say a library is just that, "a library". It is a collection of objects/functions/methods (depending on your language) and your application "links" against it and thus can use the objects/functions/methods. It is basically a file containing re-usable code that can usually be shared among multiple applications (you don't have to write the same code over and over again).
☃A framework can be everything you use in application development. It can be a library, a collection of many libraries, a collection of scripts, or any piece of software you need to create your application. The framework is just a very vague term.
❆Here's an article about some guy regarding the topic "Library vs. Framework". I personally think this article is highly arguable. It's not wrong what he's saying there, however, he's just picking out one of the multiple definitions of the framework and compares that to the classic definition of a library. E.g. he says you need a framework for sub-classing. Really? I can have an object defined in a library, I can link against it, and sub-class it in my code. I don't see how I need a "framework" for that. In some way, he rather explains how the term framework is used nowadays. It's just a hyped word, as I said before. Some companies release just a normal library (in any sense of a classical library) and call it a "framework" because it sounds fancier.
🌴Examples of libraries: Network protocols, compression, image manipulation, string utilities, regular expression evaluation, math. Operations are self-contained.
🌴Examples of frameworks: Web application system, Plug-in manager, GUI system. The framework defines the concept but the application defines the fundamental functionality that end-users care about.


Tags:
Programming Paradigm

{kind=link}
0 comments